This is the first assigned codelab on day four of the intensive. Download it here from Github to run locally or run in this Kaggle notebook.
"""Use Google Search in Generation
Google Gen AI 5-Day Intensive Course
Host: Kaggle
Day: 4
Codelab: https://www.kaggle.com/code/markishere/day-4-google-search-grounding
"""
import io
import os
from pprint import pprint
from google import genai
from google.api_core import retry
from google.genai import types
from IPython.display import HTML, Image, Markdown, display
client = genai.Client(api_key=os.environ["GOOGLE_API_KEY"])
# Define a retry policy. The model might make multiple consecutive calls automatically
# for a complex query, this ensures the client retries if it hits quota limits.
is_retriable = lambda e: (
isinstance(e, genai.errors.APIError) and e.code in {429, 503}
)
if not hasattr(genai.models.Models.generate_content, "__wrapped__"):
genai.models.Models.generate_content = retry.Retry(predicate=is_retriable)(
genai.models.Models.generate_content
)
# To enable search grounding, specify it as a tool 'google_search'
# as a parameter in `GenerateContentConfig` passed to `generate_content`
# Ask for information without search grounding
response = client.models.generate_content(
model="gemini-2.0-flash",
contents="When and where is Billie Eilish's next concert?",
)
Markdown(response.text)
# And now rerun the same query with search grounding enabled.
config_with_search = types.GenerateContentConfig(
tools=[types.Tool(google_search=types.GoogleSearch())]
)
def query_with_grounding():
response = client.models.generate_content(
model="gemini-2.0-flash",
contents="When and where is Billie Eilish's next concert?",
config=config_with_search,
)
return response
rc = query_with_grounding()
Markdown(rc.text)
# Response metadata
# Get links to search suggestions, supporting documents and information
# on how they were used.
while (
not rc.grounding_metadata.grounding_supports
or not rc.grounding_metadata.grounding_chunks
):
# If incomplete groundind data was returned, retry.
rc = query_with_grounding()
chunks = rc.grounding_metadata.grounding_chunks
for chunk in chunks:
print(f"{chunk.web.title}: {chunk.web.url}")
HTML(rc.grounding_metadata.search_entry_point.rendered_content)
supports = rc.grounding_metadata.grounding_supports
for support in supports:
pprint(support.to_json_dict())
markdown_buffer = io.StringIO()
# Print the text with footnote markers.
markdown_buffer.write("Supported text:\n\n")
for support in supports:
markdown_buffer.write(" * ")
markdown_buffer.write(
rc.content.parts[0].text[
support.segment.start_index : support.segment.end_index
]
)
for i in support.grounding_chunk_indices:
chunk = chunks[i].web
markdown_buffer.write(f"<sup>[{i + 1}]</sup>")
markdown_buffer.write("\n\n")
# Print footnotes.
markdown_buffer.write("Citations:\n\n")
for i, chunk in enumerate(chunks, start=1):
markdown_buffer.write(f"{i}. [{chunk.web.title}]({chunk.web.url})\n")
Markdown(markdown_buffer.getvalue())
# Search with tools
# Use Google search grounding and code generation tools
def show_response(response):
for p in response.candidates[0].content.parts:
if p.text:
display(Markdown(p.text))
elif p.inline_data:
display(Image(p.inline_data.data))
else:
print(p.to_json_dict())
display(Markdown('----'))
config_with_search = types.GenerateContentConfig(
tools=[types.Tool(google_search=types.GoogleSearch())],
temperature=0.0
)
chat = client.chats.create(model='gemini-2.0-flash')
response = chat.send_message(
message="What were the medal tallies, by top-10 countries, for the 2024 Olympics?",
config=config_with_search
)
show_response(response)
config_with_code = types.GenerateContentConfig(
tools=[types.Tool(code_execution=types.ToolCodeExecution())],
temperature=0.0
)
response = chat.send_message(
message="Now plot this as a Seaborn chart. Break out the medals too.",
config=config_with_code
)
show_response(response)
This is the first assigned codelab on day four of the intensive. Download it here from Github to run locally or run in this Kaggle notebook.
"""Tune Gemini Model for Custom Function
Google Gen AI 5-Day Intensive Course
Host: Kaggle
Day: 4
Codelab: https://www.kaggle.com/code/markishere/day-4-fine-tuning-a-custom-model
"""
import datetime
import email
import os
import re
import time
import warnings
from collections.abc import Iterable
import pandas as pd
import tqdm
from google import genai
from google.api_core import retry
from google.genai import types
from sklearn.datasets import fetch_20newsgroups
from tqdm.rich import tqdm as tqdmr
client = genai.Client(api_key=os.environ["GOOGLE_API_KEY"])
for model in client.models.list():
if "createTunedModel" in model.supported_actions:
print(model.name)
newgroups_train = fetch_20newsgroups(subset='train')
newgroups_test = fetch_20newsgroups(subset='test')
# View list of class names for dataset
newsgroups_train.target_names
print(newsgroups_train.date[0])
def preprocess_newsgroup_row(data):
# Extract only the subject and body.
msg = email.message_from_string(data)
text = f'{msg["Subject"]}\n\n{msg.get_payload()}'
# Strip any remaining email addresses
text = re.sub(r"[\w\.-]+@[\w\.-]+", "", text)
# Truncate the text to fit within the input limits
text = text[:40000]
return text
def preprocess_newsgroup_data(newsgroup_dataset):
# Put the points into a DataFrame
df = pd.DataFrame(
{
'Text': newsgroup_dataset.data,
'Label': newsgroup_dataset.target
}
)
# Clean up the text
df['Text'] = df['Text'].apply(preprocess_newsgroup_row)
# Match label to target name index
df['Class Name'] = df['Label'].map(lambda l: newsgroup_dataset.target_names[l])
return df
# Apply preprocessing to training and test datasets
df_train = preprocess_newsgroup_data(newgroups_train)
df_test = preprocess_newsgroup_data(newgroups_test)
df_train.head()
def sample_data(df, num_samples, classes_to_keep):
# Sample rows, selecting num_samples of each label.
df = (
df.groupby('Label')[df.columns]
.apply(lambda x: x.sample(num_samples))
.reset_index(drop=True)
)
df = df[df['Class Name'].str.contains(classes_to_keep)]
df['Class Name'] = df['Class Name'].astype('category')
return df
TRAIN_NUM_SAMPLES = 50
TEST_NUM_SAMPLES = 10
# Keep rec.* and sci.*
CLASSES_TO_KEEP = '^rec|^sci'
df_train = sample_data(df_train, TRAIN_NUM_SAMPLES, CLASSES_TO_KEEP)
df_test = sample_data(df_test, TEST_NUM_SAMPLES, CLASSES_TO_KEEP)
# Evaluate baseline performance
sample_idx = 0
sample_row = preprocess_newsgroup_row(newsgroups_test.data[sample_idx])
sample_label = newsgroups_test.target_names[newsgroups_test.target[sample_idx]]
print(sample_row)
print('---')
print('Label:', sample_label)
response = client.models.generate_content(
model='gemini-1.5-flash-001',
contents=sample_row
)
print(response.text)
# Ask the model directly in a zero-shot prompt.
prompt = "From what newsgroup does the following message originate?"
baseline_response = client.models.generate_content(
model="gemini-1.5-flash-001",
contents=[prompt, sample_row])
print(baseline_response.text)
# You can use a system instruction to do more direct prompting, and get a
# more succinct answer.
system_instruct = """
You are a classification service. You will be passed input that represents
a newsgroup post and you must respond with the newsgroup from which the post
originates.
"""
# Define a helper to retry when per-minute quota is reached.
is_retriable = lambda e: (isinstance(e, genai.errors.APIError) and e.code in {429, 503})
# If you want to evaluate your own technique, replace this body of this function
# with your model, prompt and other code and return the predicted answer.
@retry.Retry(predicate=is_retriable)
def predict_label(post: str) -> str:
response = client.models.generate_content(
model="gemini-1.5-flash-001",
config=types.GenerateContentConfig(
system_instruction=system_instruct),
contents=post)
rc = response.candidates[0]
# Any errors, filters, recitation, etc we can mark as a general error
if rc.finish_reason.name != "STOP":
return "(error)"
else:
# Clean up the response.
return response.text.strip()
prediction = predict_label(sample_row)
print(prediction)
print()
print("Correct!" if prediction == sample_label else "Incorrect.")
# Enable tqdm features on Pandas.
tqdmr.pandas()
# But suppress the experimental warning
warnings.filterwarnings("ignore", category=tqdm.TqdmExperimentalWarning)
# Further sample the test data to be mindful of the free-tier quota.
df_baseline_eval = sample_data(df_test, 2, '.*')
# Make predictions using the sampled data.
df_baseline_eval['Prediction'] = df_baseline_eval['Text'].progress_apply(predict_label)
# And calculate the accuracy.
accuracy = (df_baseline_eval["Class Name"] == df_baseline_eval["Prediction"]).sum() / len(df_baseline_eval)
print(f"Accuracy: {accuracy:.2%}")
# Tune a custom model
# Convert the data frame into a dataset suitable for tuning.
input_data = {'examples':
df_train[['Text', 'Class Name']]
.rename(columns={'Text': 'textInput', 'Class Name': 'output'})
.to_dict(orient='records')
}
# If you are re-running this lab, add your model_id here.
model_id = None
# Or try and find a recent tuning job.
if not model_id:
queued_model = None
# Newest models first.
for m in reversed(client.tunings.list()):
# Only look at newsgroup classification models.
if m.name.startswith('tunedModels/newsgroup-classification-model'):
# If there is a completed model, use the first (newest) one.
if m.state.name == 'JOB_STATE_SUCCEEDED':
model_id = m.name
print('Found existing tuned model to reuse.')
break
elif m.state.name == 'JOB_STATE_RUNNING' and not queued_model:
# If there's a model still queued, remember the most recent one.
queued_model = m.name
else:
if queued_model:
model_id = queued_model
print('Found queued model, still waiting.')
# Upload the training data and queue the tuning job.
if not model_id:
tuning_op = client.tunings.tune(
base_model="models/gemini-1.5-flash-001-tuning",
training_dataset=input_data,
config=types.CreateTuningJobConfig(
tuned_model_display_name="Newsgroup classification model",
batch_size=16,
epoch_count=2,
),
)
print(tuning_op.state)
model_id = tuning_op.name
print(model_id)
MAX_WAIT = datetime.timedelta(minutes=10)
while not (tuned_model := client.tunings.get(name=model_id)).has_ended:
print(tuned_model.state)
time.sleep(60)
# Don't wait too long. Use a public model if this is going to take a while.
if datetime.datetime.now(datetime.timezone.utc) - tuned_model.create_time > MAX_WAIT:
print("Taking a shortcut, using a previously prepared model.")
model_id = "tunedModels/newsgroup-classification-model-ltenbi1b"
tuned_model = client.tunings.get(name=model_id)
break
print(f"Done! The model state is: {tuned_model.state.name}")
if not tuned_model.has_succeeded and tuned_model.error:
print("Error:", tuned_model.error)
# Use the new model
new_text = """
First-timer looking to get out of here.
Hi, I'm writing about my interest in travelling to the outer limits!
What kind of craft can I buy? What is easiest to access from this 3rd rock?
Let me know how to do that please.
"""
response = client.models.generate_content(
model=model_id, contents=new_text)
print(response.text)
@retry.Retry(predicate=is_retriable)
def classify_text(text: str) -> str:
"""Classify the provided text into a known newsgroup."""
response = client.models.generate_content(
model=model_id,
contents=text)
rc = response.candidates[0]
# Any errors, filters, recitation, etc we can mark as a general error
if rc.finish_reason.name != "STOP":
return "(error)"
else:
return rc.content.parts[0].text
# The sampling here is just to minimise your quota usage. If you can, you should
# evaluate the whole test set with `df_model_eval = df_test.copy()`.
df_model_eval = sample_data(df_test, 4, '.*')
df_model_eval["Prediction"] = df_model_eval["Text"].progress_apply(classify_text)
accuracy = (df_model_eval["Class Name"] == df_model_eval["Prediction"]).sum() / len(df_model_eval)
print(f"Accuracy: {accuracy:.2%}")
# Compare token usage
# Calculate the *input* cost of the baseline model with system instructions.
sysint_tokens = client.models.count_tokens(
model='gemini-1.5-flash-001', contents=[system_instruct, sample_row]
).total_tokens
print(f'System instructed baseline model: {sysint_tokens} (input)')
# Calculate the input cost of the tuned model.
tuned_tokens = client.models.count_tokens(model=tuned_model.base_model, contents=sample_row).total_tokens
print(f'Tuned model: {tuned_tokens} (input)')
savings = (sysint_tokens - tuned_tokens) / tuned_tokens
print(f'Token savings: {savings:.2%}') # Note that this is only n=1.
# Tweak output token quantity
baseline_token_output = baseline_response.usage_metadata.candidates_token_count
print('Baseline (verbose) output tokens:', baseline_token_output)
tuned_model_output = client.models.generate_content(
model=model_id, contents=sample_row)
tuned_tokens_output = tuned_model_output.usage_metadata.candidates_token_count
print('Tuned output tokens:', tuned_tokens_output)
How to build an agent using LangGraph. Try code locally by downloading from Github or run it in a Kaggle notebook.
"""
Build an agent with LangGraph
Google Gen AI 5-Day Intensive Course
Host: Kaggle
Day: 3
Codelab: https://www.kaggle.com/code/markishere/day-3-building-an-agent-with-langgraph/#IMPORTANT!
"""
from pprint import pprint
from typing import Annotated, Literal
from google import genai
from IPython.display import Image
from langchain_core.messages.ai import AIMessage
from langchain_core.tools import tool
from langchain_google_genai import ChatGoogleGenerativeAI
from langgraph.graph import END, START, StateGraph
from langgraph.graph.message import add_messages
from langgraph.prebuilt import ToolNode
from typing_extensions import TypedDict
from collections.abc import Iterable
from random import randint
from langchain_core.messages.tool import ToolMessage
class OrderState(TypedDict):
"""State representing the customer's order conversation."""
# Preserves the conversaton history between nodes.
# The 'add messages' annotation indicates to LangGraphthat state
# is updated by appending returned messages, not replacing them.
messages: Annotated[list, add_messages]
# The customer's in-progress order.
order: list[str]
# Flag indicating that the order is placed and completed.
finished: bool
# The system instruction defines how the chatbot is expected to behave
# and includes rules for when to call different functions,
# as well as rules for the conversation, such as tone and what is permitted
# for discussion.
BARISTABOT_SYSINT = (
# 'system' indicates the message is a system instruction.
"system",
"You are a BaristaBot, an interactive cafe ordering system. A human will talk to you about the "
"available products you have and you will answer any questions about menu items (and only about "
"menu items - no off-topic discussion, but you can chat about the products and their history). "
"The customer will place an order for 1 or more items from the menu, which you will structure "
"and send to the ordering system after confirming the order with the human. "
"\n\n"
"Add items to the customer's order with add_to_order, and reset the order with clear_order. "
"To see the contents of the order so far, call get_order (this is shown to you, not the user) "
"Always confirm_order with the user (double-check) before calling place_order. Calling confirm_order will "
"display the order items to the user and returns their response to seeing the list. Their response may contain modifications. "
"Always verify and respond with drink and modifier names from the MENU before adding them to the order. "
"If you are unsure a drink or modifier matches those on the MENU, ask a question to clarify or redirect. "
"You only have the modifiers listed on the menu. "
"Once the customer has finished ordering items, Call confirm_order to ensure it is correct then make "
"any necessary updates and then call place_order. Once place_order has returned, thank the user and "
"say goodbye!"
"\n\n"
"If any of the tools are unavailable, you can break the fourth wall and tell the user that "
"they have not implemented them yet and should keep reading to do so.",
)
# This is the message with which the system opens the conversation.
WELCOME_MSG = "Welcome to the BaristaBot cafe. Type `q` to quit. How may I serve you today?"
# Define chatbot node
# This node will represent a single turn in a chat conversation
#
# Try using different models. The Gemini 2.0 flash model is highly capable, great with tools,
# and has a generous free tier. If you try the older 1.5 models, note that the 'pro' models are
# better at complex multi-tool cases like this, but the 'flas' models are faster and have more
# free quota.
#
# Check out the features and quota differences here:
# - https://ai.google.dev/gemini-api/docs/models/gemini
llm = ChatGoogleGenerativeAI(model="gemini-2.0-flash")
def chatbot(state: OrderState) -> OrderState:
"""The chatbot itself. A simple wrapper around the model's own chat interface."""
message_history = [BARISTABOT_SYSINT] + state["messages"]
return {"messages": [llm.invoke(message_history)]}
# Set up the initial graph based on our state definition.
graph_builder = StateGraph(OrderState)
# Add the chatbot function to the app graph as a node called 'chatbot'.
graph_builder.add_node("chatbot", chatbot)
# Define the chatbot node as the app entrypoint.
graph_builder.add_edge(START, "chatbot")
chat_graph = graph_builder.compile()
# Render the graph to visualize it.
Image(chat_graph.get_graph().draw_mermaid_png())
# The defined graph only as one node.
# So the chat will begin at __start__, execute the chatbot node and terminate.
user_msg = "Hello, what can you do?"
state = chat_graph.invoke({"messages": [user_msg]})
# The state object contains lots of informaton. Uncomment the pprint lines to see it all.
pprint(state)
# Note that the final state now has 2 messages. Our HumanMessage, and an additional AIMessage.
for msg in state["messages"]:
print(f"{type(msg).__name__}: {msg.content}")
# Can be executed as Python loop
# Here it is manually invoked once
user_msg2 = "Oh great, what kinds of latte can you make?"
state["messages"].append(user_msg2)
state = chat_graph.invoke(state)
# pprint(state)
for msg in state["messages"]:
print(f"{type(msg).__name__}: {msg.content}")
# Add a human node
# LangGraph can be looped between nodes
# This node will display the last message from the LLM to the user,
# then prompt them for their next input.
def human_node(state: OrderState) -> OrderState:
"""Display the last model message to the user and get the user's input."""
last_msg = state["message"][-1]
print("Model:", last_msg.content)
user_input = input("User: ")
# If it looks like the user is trying to quit, flag the conversaton as over.
if user_input in {"q", "quit", "exit", "goodbye"}:
state["finished"] = True
return state | {"messages": [("user", user_input)]}
def chatbot_with_welcome_msg(state: OrderState) -> OrderState:
"""The chatbot itself. A wrapper around the model's own chat interface."""
if state["messages"]:
# If there are messages, continue the conversation with the Gemini model.
new_output = llm.invoke([BARISTABOT_SYSINT]) + state["messages"]
else:
# If there are no messages, start with the welcome message.
new_output = AIMessage(content=WELCOME_MSG)
return state | {"messages": [new_output]}
# Start building a new graph.
graph_builder = StateGraph(OrderState)
# Add the chatbot and human nodes to the app graph.
graph_builder.add_node("chatbot", chatbot_with_welcome_msg)
graph_builder.add_node("human", human_node)
# Start with the chatbot again.
graph_builder.add_edge(START, "chatbot")
# The chatbot will always go to the human next.
graph_builder.add_edge("chatbot", "human")
# Create a conditional edge
def maybe_exit_human_node(state: OrderState) -> Literal["chatbot", "__end__"]:
"""Route to the chatbot, unless it looks like the user is exiting."""
if state.get("finished", False):
return END
else:
return "chatbot"
graph_builder.add_conditional_edges("human", maybe_exit_human_node)
chat_with_human_graph = graph_builder.compile()
Image(chat_with_human_graph.get_graph().draw_mermaid_png)
# The default recursion limit for traversing nodes is 25 - setting it higher means
# you can try a more complex order with multiple steps and round-trips and you can chat for longer!
config = {"recursion_limit": 100}
# Remember that this will loop forever, unless you input 'q', 'quit' or one of the other exit terms
# defined in 'human_node'.
# Uncomment this line to execute the graph:
# state = chat_with_human_graph.invoke({"messages": []}, config)
#
# Things to try:
# - Just chat! There's no ordering or menu yet.
# - 'q' to exit.
pprint(state)
# Add a "live" menu
# To create a dynamic menu to respond to changing stock levels
# There are two types of tools: stateless and stateful
# Stateless tools run automatically: get current menu: it doesn't make changes
# Stateful tools modify the order
# In LangGraph Python functions can be annotated as tools by applying @tools annotation
@tool
def get_menu() -> str:
"""Provide the latest up-to-date menu."""
# Note that this is just hard-coded text, but you could connect this to a live stock
# database, or you could use Gemini's multi-modal capabilities and take like photos
# of your cafe's chalk menu or the products on the counter, and assemble them into an input.
return """
MENU:
Coffee Drinks:
Espresso
Americano
Cold Brew
Coffee Drinks with Milk:
Latte
Cappuccino
Cortado
Macchiato
Mocha
Flat White
Tea Drinks:
English Breakfast Tea
Green Tea
Earl Grey
Tea Drinks with Milk:
Chai Latte
Matcha Latte
London Fog
Other Drinks:
Steamer
Hot Chocolate
Modifiers:
Milk options: Whole, 2%, Oat, Almond, 2% Lactose Free; Default option: whole
Espresso shots: Single, Double, Triple, Quadruple; default: Double
Caffeine: Decaf, Regular; default: Regular
Hot-Iced: Hot, Iced; Default: Hot
Sweeteners (option to add one or more): vanilla sweetener, hazelnut sweetener, caramel sauce, chocolate sauce, sugar free vanilla sweetener
Special requests: any reasonable modification that does not involve items not on the menu, for example: 'extra hot', 'one pump', 'half caff', 'extra foam', etc.
"dirty" means add a shot of espresso to a drink that doesn't usually have it, like "Dirty Chai Latte".
"Regular milk" is the same as 'whole milk'.
"Sweetened" means add some regular sugar, not a sweetener.
Soy milk has run out of stock today, so soy is not available.
"""
# Add the tool to the graph
# Define the tools and create a "tools" node.
tools = [get_menu]
tool_node = ToolNode(tools)
# Attach the tools to the model so that it knows what it can call.
llm_with_tools = llm.bind_tools(tools)
def maybe_route_to_tools(state: OrderState) -> Literal["tools", "human"]:
"""Route between human or tool nodes, depending if a tool call is made."""
if not (msgs := state.get("messages", [])):
raise ValueError(f"No messages found when parsing state: {state}")
# Only route based on the last message.
msg = msgs[-1]
# When the chatbot returns tool_calls, rout to the "tools" node.
if hasattr(msg, "tool_calls") and len(msg.tool_calls) > 0:
return "tools"
else:
return "human"
def chatbot_with_tools(state: OrderState) -> OrderState:
"""The chatbot with tools. A simple wrapper around the model's own chat interface."""
defaults = {"order": [], "finished": False}
if state["messages"]:
new_output = llm_with_tools.invoke(
[BARISTABOT_SYSINT] + state["messages"]
)
else:
new_output = AIMessage(content=WELCOME_MSG)
# Set up some defaults if not already set, then pass through the provided state,
# overriding only the "messages" field.
return defaults | state | {"messages": [new_output]}
graph_builder = StateGraph(OrderState)
# Add the nodes, including the new tool_node.
graph_builder.add_node("chatbot", chatbot_with_tools)
graph_builder.add_node("human", human_node)
graph_builder.add_node("tools", tool_node)
# Chatbot may go to tools, or human.
graph_builder.add_conditional_edges("chatbot", maybe_route_to_tools)
# Human may go back to chatbot, or exit.
graph_builder.add_conditional_edges("human", maybe_exit_human_node)
# Tools always route back to chat afterwards.
graph_builder.add_edge("tools", "chatbot")
graph_builder.add_edge(START, "chatbot")
graph_with_menu = graph_builder.compile()
Image(graph_with_menu.get_graph().draw_mermaid_png())
# Remember that you have not implemented ordering yet, so this will loop forever,
# unless you input `q`, `quit` or one of the other exit terms defined in the
# `human_node`.
# Uncomment this line to execute the graph:
state = graph_with_menu.invoke({"messages": []}, config)
# Things to try:
# - I'd love an espresso drink, what have you got?
# - What teas do you have?
# - Can you do a long black? (this is on the menu as an "Americano" - see if it can
# figure it out)
# - 'q' to exit.
pprint(state)
# Handle orders
# Update state to track an order and provide simple tools that update the state.
# You will need to be explicit as the model should not directly have access to
# the app's internal state.
#
# These functions have no body; LangGraph does not allow @tools to update the
# conversation state, so you will implement a separate node to handle state
# updates.
@tool
def add_to_order(drink: str, modifiers: Iterable[str]) -> str:
"""Adds the specified drink to the customer's order, including any modifiers.
Returns:
The updated order in progress.
"""
@tool
def confirm_order() -> str:
"""Asks customer if the order is correct.
Returns:
The user's free-text response.
"""
@tool
def get_order() -> str:
"""Returns the users order so far. One item per line."""
@tool
def clear_order():
"""Removes all items from the user's order."""
@tool
def place_order() -> int:
"""Sends the order to the barista for fulfillment.
Returns:
The estimated number of minutes until the order is ready.
"""
def order_node(state: OrderState) -> OrderState:
"""The ordering node. This is where the order state is manipulated."""
tool_msg = state.get("messages", [])[-1]
order = state.get("order", [])
outbound_msgs = []
order_placed = False
for tool_call in tool_msg.tool_calls:
if tool_call["name"] == "add_to_order":
# Each order item is just a string. This is where it is assembled.
# as "drink (modifiers, ...)".
modifiers = tool_call["args"]["modifiers"]
modifier_str = ", ".join(modifiers) if modifiers else "no modifiers"
order.append(f"{tool_call["args"]["drink"]} ({modifier_str}))
response = "\n".join(order)
elif tool_call["name"] == "confirm_order":
# We could entrust the LLM to do order confirmation, but it is a good practice to
# show the user the exact data that comprises their order so that what they confirm
# precisely matches the order that goes to the kitchen - avoiding hallucination
# or reality skew.
# In a real scenario, this is where you would connect your POS screen to show the
# order to the user.
print("Your order:")
if not order:
print(" (no items)")
for drink in order:
print(f" {drink}")
response = input("Is this correct?")
elif tool_call["name"] == "get_order":
response = "\n".join(order) if order else "(no order)"
elif tool_call["name"] == "clear_order":
order.clear()
response = None
elif tool_call["name"] == "place_order":
order_text = "\n".join(order)
print("Sending order to kitchen!")
print(order_text)
# TODO: Implement cafe.
order_placed = True
response = randint(1, 5) # ETA in minutes
else:
raise NotImplementedError(f"Unknown tool call: {tool_call["name"]}")
# Record the tool results as tool message.
outbound_msgs.append(
ToolMessage(
content=response,
name=tool_call["name"],
tool_call_id=tool_call["id"]
)
)
return {"messages": outbound_msgs, "order": order, "finished": order_placed}
def maybe_route_to_tools(state: OrderState) -> str:
"""Route between chat and tool nodes if a tool call is made."""
if not (msgs := state.get("messages", [])):
raise ValueError(f"No messages found when parsing state: {state}")
msg = msgs[-1]
if state.get("finished", False):
# When an order is placed, exit the app. The system instruction indicates
# that the chatbot should say thanks and goodbye at this point, so we can exit
# cleanly.
return END
elif hasattr(msg, "tool_calls") and len(msg.tool_calls) > 0:
# Route to 'tools' node for any automated tool calls first.
if any(
tool["name"] in tool_node.tools_by_name,keys() for tool in msg.tool_calls
):
return "tools"
else:
return "ordering"
else:
return "human"
# Define the graph so the LLM knows about the tools to invoke them.
# Auto-tools will be invoked automatically by the ToolNode
auto_tools = [get_menu]
tool_node = ToolNode(auto_tools)
# Order-tools will be handled by the order node.
order_tools = [add_to_order, confirm_order, get_order, clear_order, place_order]
# The LLM needs to know about all of the tools, so specify everything here
llm_with_tools = llm.bind_tools(auto_tools + order_tools)
graph_builder = StateGraph(OrderState)
# Nodes
graph_builder.add_node("chatbot", chatbot_with_tools)
graph_builder.add_node("human", human_node)
graph_builder.add_node("tools", tool_node)
graph_builder.add_node("ordering", order_node)
# Chatbot -> (ordering, tools, human, END)
graph_builder.add_conditional_edges("chatbot", maybe_route_to_tools)
# Human -> (chatbot, END)
graph_builder.add_conditional_edges("human", maybe_exit_human_node)
# Tools (both kinds) always route back to chat afterwards.
graph_builder.add_edge("tools", "chatbot")
graph_builder.add_edge("ordering", "chatbot")
graph_builder.add_edge(START, "chatbot")
graph_with_order_tools = graph_builder.compile()
Image(graph_with_order_tools.get_graph().draw_mermaid.png())
# Uncomment this line to execute the graph:
state = graph_with_order_tools.invoke({"messages": []}, config)
# Things to try:
# - Order a drink!
# - Make a change to your order.
# - "Which teas are from England?"
# - Note that the graph should naturally exit after placing an order.
pprint(state)
# Uncomment this once you have run the graph from the previous cell.
pprint(state["order"])
When learning a new language, as I’m currently pursuing with French, once you get past the basics of conjugation, grammar and pronunciation, becoming fluent requires a deeper understanding of the language. It is necessary to not only know how to speak the language but also know the nuances of a langauge including common usage patterns, useful related phrases, and linguistic and historical facts. How certain phrases are commonly use. What does it sound like spoken versus written. What language rules cause a change in spelling and word groupings. These are all insights that would be helpful to me as a second language learner to have when studying a language.
For example, in French the phrase “pas de” doesn’t change even if it is followed by a plural noun. It is used as “pas de viandes” as well as “pas de fromage”. This and other similar examples enrich and enhance french-language learning. A language learner has to be able to take notes on these variations and practice them.
Goals
During my studies, I often have to use multiple websites and apps to get the additional information I need to understand the grammar, spelling, and language rules to name a few. Often, It’s more helpful to get additional details and examples.
The goal of my project was to create a French language advisor to help me achieve my goal of being fluent in the French language. Currently, I am working to be fluent in French and I’m currently at CEFR 43 where I can read, write and speak about every things. At this point in my learning, it’s important to understand and explore the language nuances to foster thinking “in French”, versus just learning grammar, vocabulary, and conjugations.
I wanted to see if a chatbot could eliminate the need for multiple apps and websites to get the information I need.
The goals were to:
Create a model that can use an agent, Google Search grounding, and retrieval augmented generation (RAG) to supplement and support my French language studies
Have the model offer suggestions, ideas, examples and interesting information and facts about the French language
Include something interesting, funny and/or popular culture references
Features
The primary feature of the model was to give me the ability to ask any question and receive results that may refer to embedded texts (RAG) or Google search results. I needed the ability to input a word, phrase or sentence in French, and receive an appropriate response, preferably in French.
Chatbot features
Get interesting French language details including grammar, composition, and spelling with Google search grounding.
Create a domain-specific LLM: Add French language notes and documents
Use existing texts as input for RAG to reference French textbooks and documents
LangGraph to manage the conversation and its details
Implementation
This solution leverages LangGraph, Gemini’s Google Search, RAG and functions. The steps used to implement this solution are outlined here. The initial stages of my project were to create a basic graph that included Google searches, client instantiation and creating embeddings. Once that was tested then add and integrate RAG to provide a richer learning experience.
Prepare Data: The PDFs for RAG are French-language textbooks that were imported then converted to Documents (object type) before embedding them using Google’s models/text-embedding-004. Once the embeddings were created, they were stored in a Chroma vectorstore database.
defcreate_embeddings(text:str)-> List[float]:"""Create embeddings for a given text.""" response = client.models.embed_content(model=EMBEDDING_MODEL,contents=text,config=types.EmbedContentConfig(task_type="semantic_similarity"),)return response.embeddings
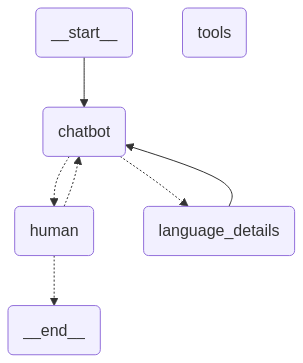
Build Agents & Functions: The chatbot consists of LangGraph nodes, functions, conditional edges and edges as seen in this mermaid graph.
Search grounding: Google search is used to return augmented results such as common usage examples and conjugations. The wrapper used is ChatGoogleGenerativeAI. It’s part of the langchain_google_genai package. It was configured with temperature and top_p.
LangGraph Nodes: This was the most challenging for me as I had to first learn LangGraph beyond the codelabs to understand it. Once I understood, I was able to create and sequence the nodes and edges to get the model behavior and output that I wanted.
# Create and display the graphworkflow.add_node("chatbot", chatbot)workflow.add_node("human", human_node)workflow.add_node("tools", tools_node)workflow.add_node("language_details", language_details_node)# Chatbot may go to tools, or human.workflow.add_conditional_edges("chatbot", maybe_route_to_tools)# Human may go back to chatbot, or exit.workflow.add_conditional_edges("human", maybe_exit_human_node)# Define chatbot node edgesworkflow.add_edge("language_details","chatbot")# Set graph start and compileworkflow.add_edge(START,"chatbot")workflow_with_translation_tools = workflow.compile()
Reflection and Learning
Prior to participating in the Google Gen AI 5-Day Intensive, I was unfamiliar with LangGraph, RAG, and agents. Now, I understand the flexibility and promise of LangGraph, RAG and agentic LLMs to allow models to be more flexible and relevant.
Some of what I’ve had to learn are following:
The types Gemini models I can use for embedding and the chatbot. In this case, I used the text-embedding-004 embedding model without experiencing any issues.
How to configure chatbot and embedding clients. Both clients were easy to configure and were set once and done.
How Google AI can be used in a LangGraph graph. I used two major packages, GoogleGenerativeAIEmbeddings and ChatGoogleGenerativeAI. Using either package was easy because the API and code documentaion was very good.
The difference between conditional edges and edges and how to create them. This was a bit tricky to decide what should be a tool versus a function for a conditional edge, versus a node. I also had to consider which logic should be place where and how the output should be handled. It took several graph iterations to get almost the way I like it. For the purposes of the capstone, it works as I intended.
How to import and extract text from PDFs. Importing and extracting text from PDF files was easy, as long as the PDF contained actual text and not images. To keep the scope of the project within my timeframe, I only wanted to work with PDFs that contained text.
How to embed documents for RAG contexts. Document embedding took several minutes for three decent-sized PDFs. It was the most time-consuming part of testing. It’s easy to see where as the set of documents I embed grows, more time and resources will be required.
Creating a Chroma vectorstore database. Creating and retrieving the vectorstore contents was fairly straightforward. It worked consistently locally and in the Kaggle Notebook.
Creating, updating and accessing a graph’s State object. I would have liked to have more time to master the state object but I was able to understand enough to make it work for my project. I would have liked to customize the state more but didn’t have the time to do so. I did find it to be a convenient resource to access messages no matter where it was invoked in the graph.
Create multiple tools and nodes to be used in the graph. I knew what tools I wanted to include based on the resources and tools I currently use when studying French. The goal was to consolidate the information I receive from multiple sources into a single one. But, there are other tools that would enrich my learning. For example, the ability to get rich text and image responses.
Using a prompt template to create and use basic prompts. I didn’t get as much time to investigate creating and using PromptTemplates. I know they could be useful for managing and transforming user input and I will be exploring them further beyond this project.
In addition, since I wrote the code locally in Zed, it took some time and effort to transform the code for a Kaggle notebook. One of the issues I had was that the dependencies initially installed in Kaggle’s environment caused import and dependency resolution errors. It took some time to make sure that the dependencies that worked locally were the same on Kaggle. In hindsight, I’m glad I developed it locally versus starting in a notebook
The Bigger Picture
Thinking beyond this capstone project, language learners need a wise companion to provide information and guidance. The companion would be a language note-taking app with an AI companion that would make suggestions about language rules, common usages, examples and comparisons. While taking notes, or when asked a question, an AI companion would be displayed in a sidebar with context rich details, and unique information and historical facts. This way, as they learn, they get to consider and contrast what they’ve learned. This would create a richer learning environment to motivate and encourage fluency. It can include images too.
This project is about taking the first steps to creating such a companion that will use the keywords, phrases and sentences I input to give me more context and nuance about it’s meaning, common usage patterns and interesting cultural and historical facts. It’s about going beyond the basics to to become immersed in French, especially if you don’t get to live in or visit a francophone country.
Ultimately, it can be developed into an AI-enabled, context-aware application. The AI integrated into the app would be a wise language advisor to help me learn the language. This would be similar to what happens currently with AI-enabled coding apps such as Zed, but more engaging. The AI assistant would remain aware of what I’m typing and offer context-rich suggestions. It would also allow the user to provide instruction at the start of the session for what their learning target is. Once the AI has this, it can then provide a richer learning experience.
This chatbot is the first step in realizing this vision. I can now input anything in french get a variety of details about it, including making additional requests for grammar, gender, and popular culture details.
The next steps for my French language assistant is to continue refine and update the graph, then create a user-friendly interface, before considering an app or website.
Codelab 1/2 from day one. The code lab is here in Kaggle and you can download it to run locally on Github.
"""
Evaluation and Structured Output
Google Gen AI 5-Day Intensive Course
Host: Kaggle
Day: 1
Kaggle: https://www.kaggle.com/code/markishere/day-1-evaluation-and-structured-output
"""
import enum
import os
from google import genai
from google.api_core import retry
from google.genai import types
from IPython.display import Markdown, display
client = genai.Client(api_key=os.environ["GOOGLE_API_KEY"])
# Automated retry
is_retriable = lambda e: (
isinstance(e, genai.errors.APIError) and e.code in {429, 503}
)
genai.models.Models.generate_content = retry.Retry(predicate=is_retriable)(
genai.models.Models.generate_content
)
# if not hasattr(genai.models.Models.generate_content, '__wrapped__'):
# genai.models.Models.generate_content = retry.Retry(
# predicate=is_retriable)(genai.models.Models.generate_content)
# Evaluation
# Understand model performance
# Get the file locally first
# !wget -nv -O gemini.pdf https://storage.googleapis.com/cloud-samples-data/generative-ai/pdf/2403.05530.pdf
document_file = client.files.upload(file="/Users/renise/Documents/Python/gen_ai/day_one/gemini.pdf")
print("\n")
print(document_file)
print("\n")
print("\nSummarize a document\n")
# Summarize a document
def summarize_doc(request: str) -> str:
"""Execute the request on the uploaded document."""
# Set the temperature low to stabilize the output.
config = types.GenerateContentConfig(temperature=0.0)
response = client.models.generate_content(
model="gemini-2.0-flash",
config=config,
contents=[request, document_file],
)
return response.text
request = "Tell me about the training process used here."
summary = summarize_doc(request)
# display(Markdown(summary + "\n-----"))
print("\n\n")
# Define an evaluator
SUMMARY_PROMPT = """\
# Instruction
You are an expert evaluator. Your task is to evaluate the quality of the responses generated by AI models.
We will provide you with the user input and an AI-generated responses.
You should first read the user input carefully for analyzing the task, and then evaluate the quality of the responses based on the Criteria provided in the Evaluation section below.
You will assign the response a rating following the Rating Rubric and Evaluation Steps. Give step-by-step explanations for your rating, and only choose ratings from the Rating Rubric.
# Evaluation
## Metric Definition
You will be assessing summarization quality, which measures the overall ability to summarize text. Pay special attention to length constraints, such as in X words or in Y sentences. The instruction for performing a summarization task and the context to be summarized are provided in the user prompt. The response should be shorter than the text in the context. The response should not contain information that is not present in the context.
## Criteria
Instruction following: The response demonstrates a clear understanding of the summarization task instructions, satisfying all of the instruction's requirements.
Groundedness: The response contains information included only in the context. The response does not reference any outside information.
Conciseness: The response summarizes the relevant details in the original text without a significant loss in key information without being too verbose or terse.
Fluency: The response is well-organized and easy to read.
## Rating Rubric
5: (Very good). The summary follows instructions, is grounded, is concise, and fluent.
4: (Good). The summary follows instructions, is grounded, concise, and fluent.
3: (Ok). The summary mostly follows instructions, is grounded, but is not very concise and is not fluent.
2: (Bad). The summary is grounded, but does not follow the instructions.
1: (Very bad). The summary is not grounded.
## Evaluation Steps
STEP 1: Assess the response in aspects of instruction following, groundedness, conciseness, and verbosity according to the criteria.
STEP 2: Score based on the rubric.
# User Inputs and AI-generated Response
## User Inputs
### Prompt
{prompt}
## AI-generated Response
{response}
"""
# Define a structured enum class to capture the result.
class SummaryRating(enum.Enum):
VERY_GOOD = 5
GOOD = 4
OK = 3
BAD = 2
VERY_BAD = 1
def eval_summary(prompt, ai_response):
"""Evaluate the generated summary against the prompt."""
chat = client.chats.create(model="gemini-2.0-flash")
# Generate the full text response
response = chat.send_message(
message=SUMMARY_PROMPT.format(prompt=prompt, response=ai_response)
)
verbose_eval = response.text
# Coerce into desired structure
structured_output_config = types.GenerateContentConfig(
response_mime_type="text/x.enum",
response_schema=SummaryRating
)
response = chat.send_message(
message="Convert the final score.",
config=structured_output_config
)
structured_eval = response.parsed
return verbose_eval, structured_eval
text_eval, struct_eval = eval_summary(
prompt=[request, document_file],
ai_response=summary
)
Markdown(text_eval)
# Play with the summary prompt
new_prompt = "Explain like I'm 5 the training process"
# Try:
# ELI5 the training process
# Summarise the needle/haystack evaluation technique in 1 line
# Describe the model architecture to someone with a civil engineering degree
# What is the best LLM?
if not new_prompt:
raise ValueError("Try setting a new summarization prompt.")
def run_and_eval_summary(prompt):
"""Generate and evaluate the summary using the new prompt."""
summary = summarize_doc(new_prompt)
display(Markdown(summary + "\n-----"))
text, struct = eval_summary([new_prompt, document_file], summary)
display(Markdown(text + "\n-----"))
print(struct)
run_and_eval_summary(new_prompt)
In late March 2025, Google held a generative AI 5-day intensive for developers. It was hosted by Kaggle and included daily codelabs for the first four days. The course included daily live video sessions on YouTube with insights from current Google employees.
Source: Google’s The Keyword Blog
The course featured:
YouTube videos: Each day a one hour live session hosted by Google that featured a Q&A codelab reviews.
Discord server: The Kaggle server gave attendees the opportunity to ask questions, share ideas and get support.
Kaggle notebooks: Codelabs were hosted in Kaggle notebooks and the day one notebook is here as an example.
The course is targeted towards developers who already know how to write code. If you’re new to coding, the code will be more challenging because the codelabs require you to read the provided code.
It taught us how to use Vertex AI and Gemini APIs to implement generative AI for a range of use cases. We learned about agents, functions, creating custom models, how to fine tune a model, to name a few. The course is structured to provide coding examples that developers can use to develop there own generative AI solutions.
To take a future offering of the course, check this page for when another session will be offered. The first sesson was offered in November 2024 and the second was held in April 2025.
Cookie Consent
We use cookies to improve your experience on our site. By using our site, you consent to cookies.
Contains information related to marketing campaigns of the user. These are shared with Google AdWords / Google Ads when the Google Ads and Google Analytics accounts are linked together.
90 days
__utma
ID used to identify users and sessions
2 years after last activity
__utmt
Used to monitor number of Google Analytics server requests
10 minutes
__utmb
Used to distinguish new sessions and visits. This cookie is set when the GA.js javascript library is loaded and there is no existing __utmb cookie. The cookie is updated every time data is sent to the Google Analytics server.
30 minutes after last activity
__utmc
Used only with old Urchin versions of Google Analytics and not with GA.js. Was used to distinguish between new sessions and visits at the end of a session.
End of session (browser)
__utmz
Contains information about the traffic source or campaign that directed user to the website. The cookie is set when the GA.js javascript is loaded and updated when data is sent to the Google Anaytics server
6 months after last activity
__utmv
Contains custom information set by the web developer via the _setCustomVar method in Google Analytics. This cookie is updated every time new data is sent to the Google Analytics server.
2 years after last activity
__utmx
Used to determine whether a user is included in an A / B or Multivariate test.
18 months
_ga
ID used to identify users
2 years
_gali
Used by Google Analytics to determine which links on a page are being clicked
30 seconds
_ga_
ID used to identify users
2 years
_gid
ID used to identify users for 24 hours after last activity
24 hours
_gat
Used to monitor number of Google Analytics server requests when using Google Tag Manager